
Revisiting Machine Learning for Predictive Modeling for Stroke from Electronic Health Records
Article Sidebar
Main Article Content
Abstract
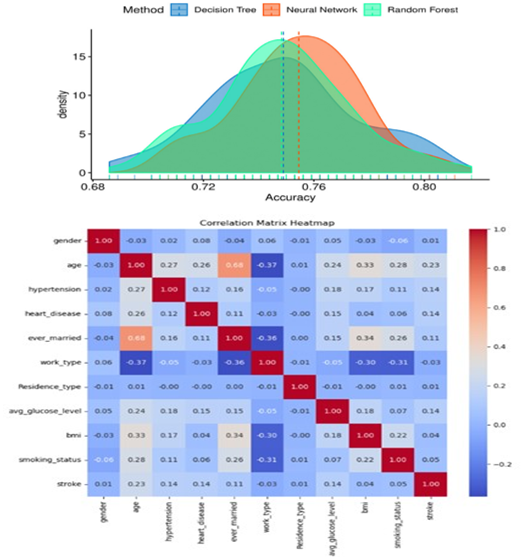
Stroke is a big worldwide threat with serious health and economic implications. To solve this, researchers are developing automated stroke prediction algorithms, allowing for early intervention and perhaps saving lives. Machine learning (ML) techniques have emerged as powerful tools for predicting stroke risk based on patient data. This study explores the application of various ML algorithms, including logistic regression, decision trees, support vector machines, and k-nearest neighbors, for stroke prediction. The models are trained on historical data from patients with known stroke outcomes and evaluated on their ability to classify individuals into stroke-risk categories accurately. ML techniques are being increasingly adapted for use in the medical field because of their high accuracy. The main contribution of this study is a stacking method that achieves a high performance that is validated by various metrics, such as AUC, precision, recall, F-measure, and accuracy. This study also shows how different ML models can predict strokes by analyzing factors such as age, gender, accompanying habits, and personal lifestyle. It is quite essential to understand the risk factors that make a patient more susceptible to strokes, thus some factors make stroke prediction much easier. This research offers an analysis of the factors that enhance the stroke prediction process based on electronic health records.
Downloads
Article Details

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite



