
Text to Image using Deep Learning: A Survey
Article Sidebar
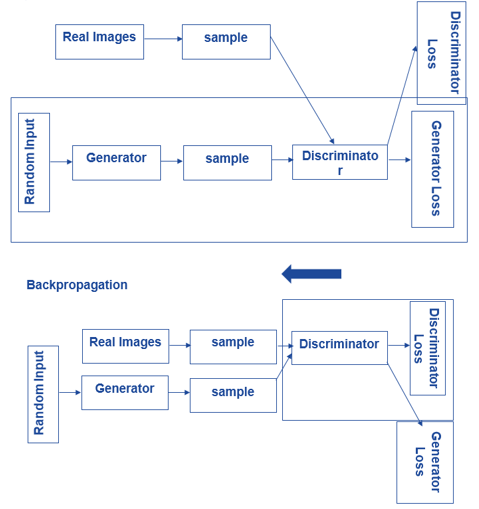
Main Article Content
Abstract
Text-to-image synthesis is an exciting marriage of natural language processing and computer vision for image synthesis from textual descriptions. This survey explores the discussed accomplishment of value in an industry that is rapidly evolving. Various attention mechanisms proposed by models such as AttnGAN have been discovered to improve fine-grained text-visual correspondences and hence deliver higher quality outputs. Comprehensive reviews of the text generation neural network have provided the base upon which various architectures and applications would be identified and investigated. Conditional GAN has defined how an image becomes a suitable image given a piece of text; methodological directions addressing reproducible human evaluation framework have established benchmarks for qualitative assessments of model performance. Semantic disentanglement methods also tackle the need for controlled generation, facilitating better interpretability and diversity. Bringing these developments together in one review, this survey discusses the issues now confronting researchers, such as computational complexity and consistency of evaluation, before describing the ways in which text-to-image generation will develop to enhance its academic and applied uses
Downloads
Article Details

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite



